- TerminusDB
- TerminusCMSProduct Info
- VectorLinkTechnical Overview
- Docs
- Community
- BlogCATEGORIES
- Pricing

- TerminusDB
- TerminusCMSProduct Info
- VectorLinkTechnical Overview
- Docs
- Community
- BlogCATEGORIES
- Pricing


Stay up to date in the world of data by signing up to the TerminusDB newsletter.
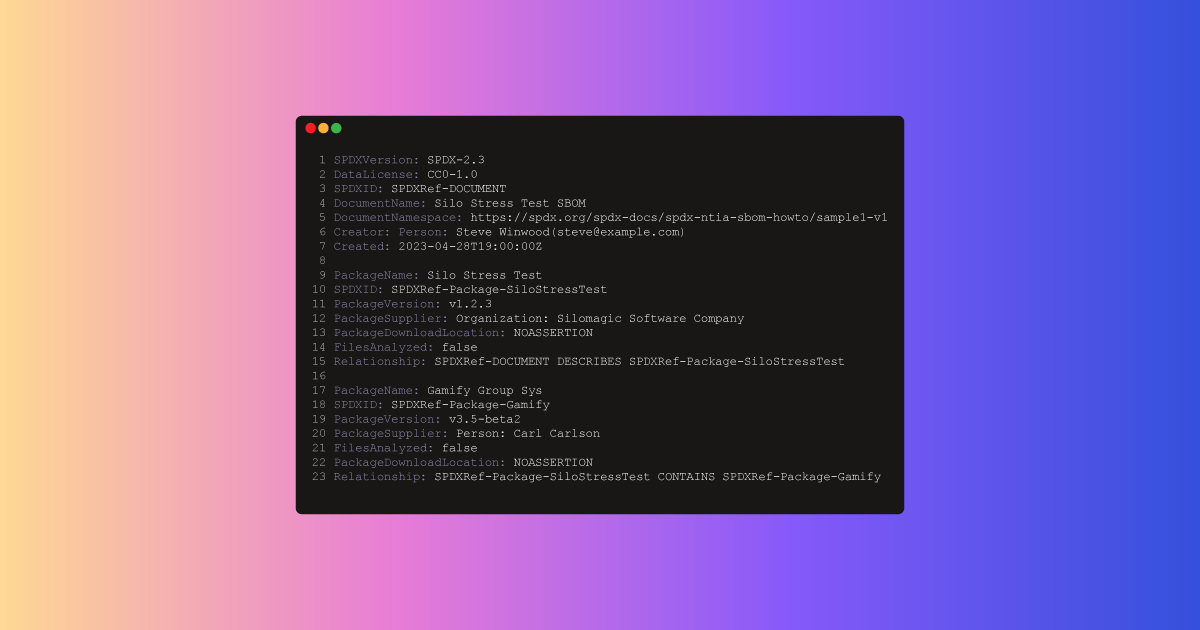
An SBOM identifies, tracks, and maintains a list of all the software components and dependencies, this article looks at how headless CMS is a good solution to manage this process.
Using declarative logic and semantic descriptions, we build a low-code app for straight-through processing of insurance claims.
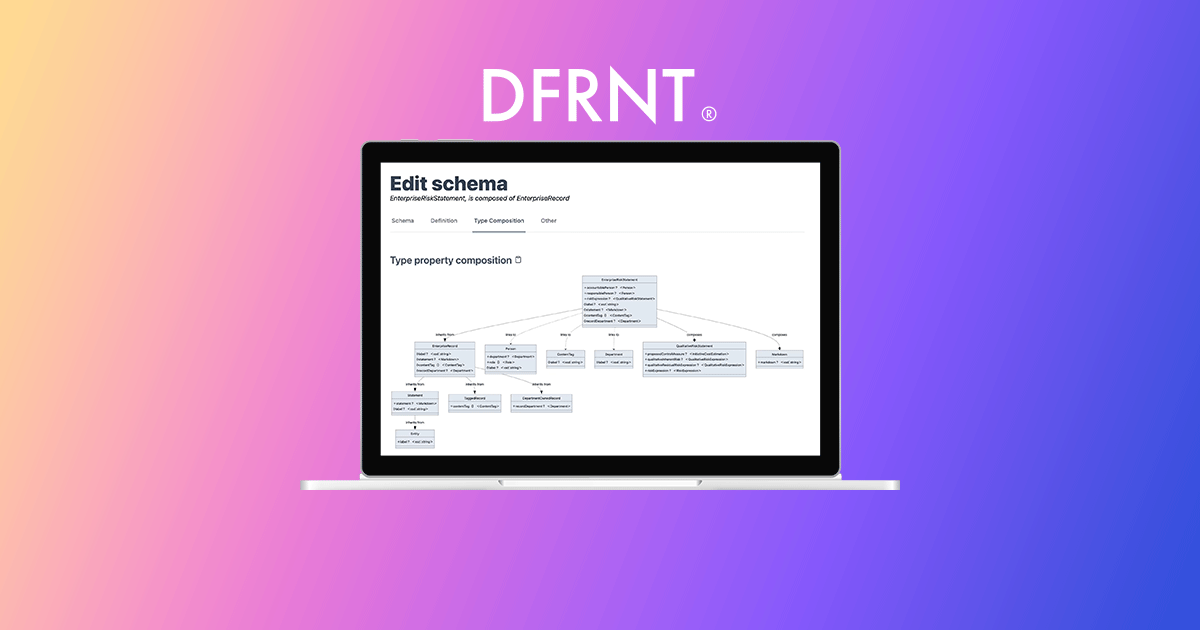
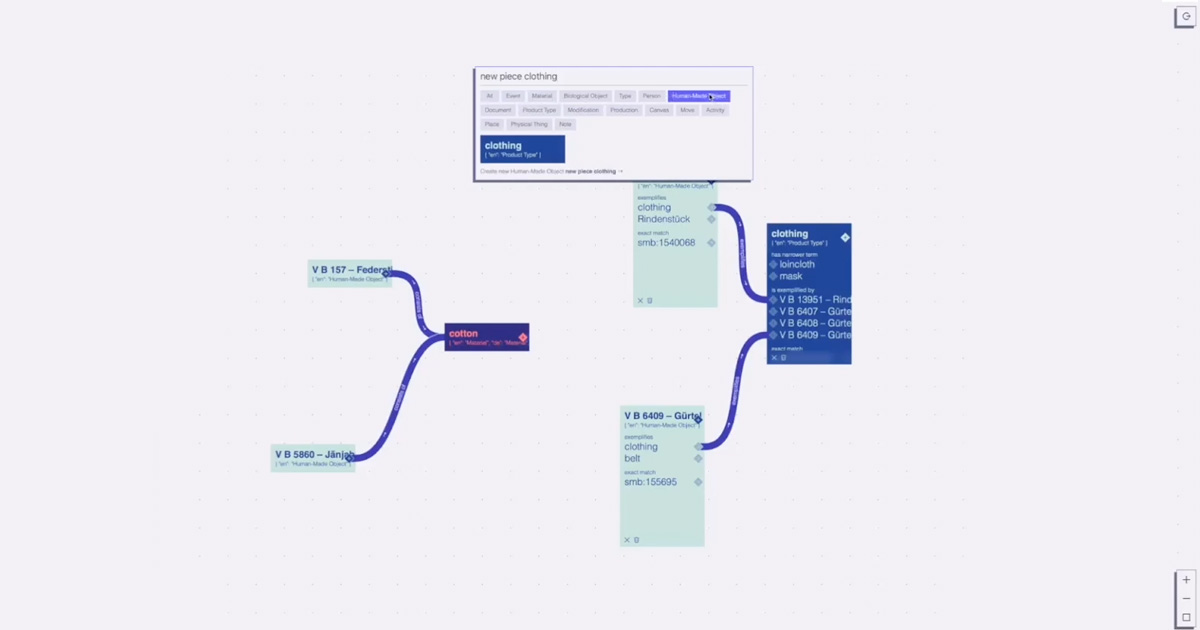
DFRNT is a tool for change makers to model and build data products. With advanced data modelling and graph visualisation, data architects can tackle complex problems.
See how TerminusDB is used as an academic research database by Amazonia Future Lab to connect collections & local knowledge.